Evaluating LLMs at Scale

Image generated by Google Gemini
Imagine deploying a core algorithmic change to a financial platform handling $1.6 billion in monthly transactions, and instead of relying on a suite of deterministic test cases, your senior engineer takes a quick look at terminal output and says, "Looks good to me." In traditional software engineering, this level of negligence would be career-ending. Yet, this is exactly the standard operating procedure for a frightening majority of enterprise Generative AI deployments today.
Over the last two years, the barrier to entry for building Artificial Intelligence applications has plummeted. Connecting an API to a Large Language Model (LLM) takes minutes, creating an illusion of simplicity. However, unlike traditional code which is deterministic—meaning the same inputs reliably produce the same outputs—LLMs are inherently probabilistic. This fundamental shift requires entirely new paradigms for quality assurance. The Pew Research Center found that highly publicized AI failures have left "a majority of Americans (52%) feeling more concerned than excited about the increased use of artificial intelligence" (Tyson and Kikuchi). Despite this crisis of user trust, many teams still rely on "vibe checks," where developers casually poke at a prompt sandbox to see if the model's tone feels correct before pushing to production.
This approach is fundamentally incompatible with the reality of building software that moves markets or manages highly sensitive data. In the enterprise, if a product team cannot comprehensively and programmatically evaluate an LLM's output against rigorous metrics, they run an unacceptable business risk; relying on "gut feel" must be replaced with automated, continuous CI/CD evaluation pipelines.
The danger of deploying probabilistic systems without structural evaluation is the insidious nature of silent failure. Traditional systems fail loudly. If a database cluster drops, warning bells ring, PagerDuty alerts fire, and dashboards immediately reflect the downtime. When a Large Language Model fails, however, it does not throw an error code. Instead, it confidently returns a perfectly formatted JSON object that contains a complete hallucination—perhaps advising a client to take a prohibited action, or misrouting a high-value customer service claim. I have seen the panic that arises in enterprise war rooms when a minor tweak to a system prompt magically improves the handling of localized edge cases, but silently breaks core workflows across ten other unseen variables. Without an automated safety net, engineering velocity grinds to a halt because the team becomes paralyzed by the very real fear that any change could trigger a catastrophic, invisible regression.
To break free of this paralysis, teams must embrace the "LLM-as-a-Judge" architecture built upon a "Golden Dataset." This means standardizing a curated library of hundreds—and eventually thousands—of real-world user interactions. These interactions cover the mundane "happy path," but more importantly, they map adversarial prompt injections, data scraping attempts, and complex multi-turn reasoning traps. As a product leader who has scaled these exact architectures, I can attest that human review simply does not scale. Instead, the most effective strategy is to deploy a secondary, highly deterministic model running at temperature zero to independently grade the production model's outputs. You do not ask the judge if the answer reads well; you ask it strictly binary questions. Did the model pull information solely from the provided RAG context? Did it successfully decline a prohibited topic?
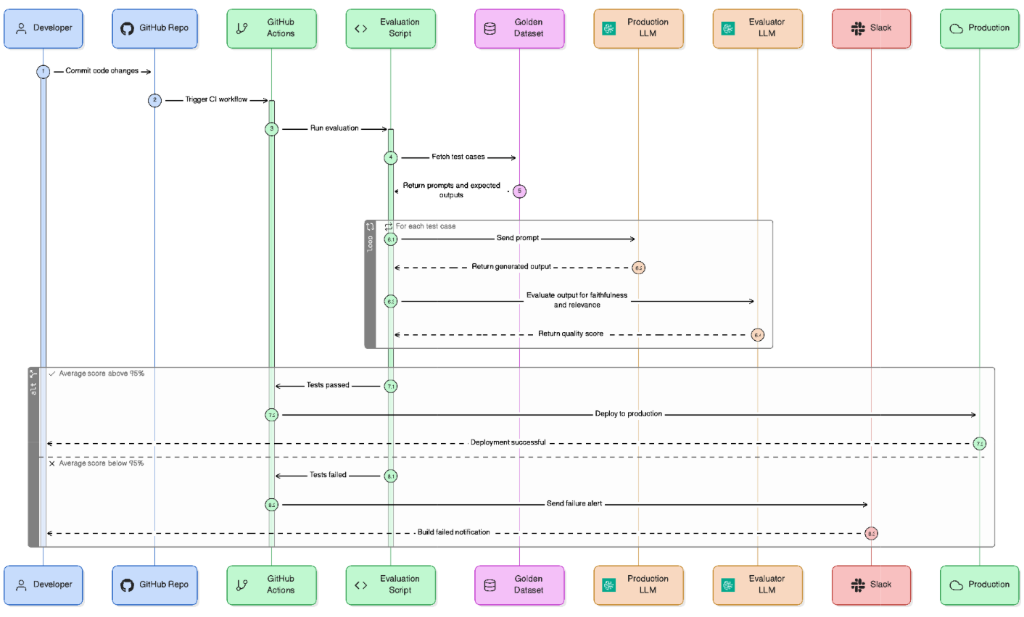
The numbers underlying this shift from manual to programmatic evaluation are undeniable. Consider a standard enterprise release cycle: manual sandbox testing of 50 edge cases might take an engineer three hours, whereas an automated CI/CD pipeline leveraging an LLM-as-a-Judge can evaluate 500 edge cases in under two minutes for less than $4.00 in total API compute (OpenAI). By integrating this evaluation layer directly into GitHub Actions or GitLab CI, the pipeline can automatically block any pull request where the model's faithfulness score drops beneath a strict 99% threshold. This is how you reclaim deployment velocity safely.
The era of shipping artificial intelligence based on gut feeling and flashy sandbox demos is rapidly coming to an end. As we transition from building software that computes to software that decides, our mandate as product leaders is no longer just to build intelligent systems, but to build structurally trustworthy ones.
Works Cited Tyson, Alec, and Emmy Kikuchi. “Growing public concern about the role of artificial intelligence in daily life.” Pew Research Center, 28 Aug. 2023, www.pewresearch.org/short-reads/2023/08/28/growing-public-concern-about-the-role-of-artificial-intelligence-in-daily-life/.