From Prototype to Production

Image generated by Google Gemini
It is a recurring scene that haunts modern software engineering departments: An executive, having just spent the weekend scrolling through viral Artificial Intelligence demos on social media, turns to their lead product manager and asks a seemingly innocent question. "If a lone developer built an autonomous customer service agent in three hours using an open-source library," the executive wonders, "why is it taking our department six months to launch our AI copilot?"
The answer, inevitably met with institutional frustration, is that the prototype constitutes roughly ten percent of the total effort required to ship software. The Generative AI ecosystem is currently flooded with high-level orchestrators like LangChain and LlamaIndex that allow developers to connect an API to a dataset in a single afternoon. This accessibility has created a dangerous false equivalence across the industry. Boardrooms and non-technical stakeholders wrongly assume that because producing a convincing output is easy, building a scalable, profitable, and secure product using that output must also be easy.
The skillset required to build a conversational demo in a localized Jupyter notebook shares virtually no overlap with the architectural rigor required to survive a live deployment. Transitioning an AI agent from a weekend prototype to enterprise production requires abandoning naive context stuffing and instead implementing strict semantic routing, deterministic guardrails, and deep observability to protect both business margins and user safety.
The emotional toll on engineering teams forced to transition fragile prototypes into production is immense. When leadership demands that a "weekend hack" be scaled immediately to 10,000 daily active users, developers are placed in an impossible situation. I have witnessed talented teams suffer severe burnout as they attempt to maintain massive, over-stuffed LLM context windows that frequently crash or, worse, confidently lie to users. The stress of managing a stochastic, unpredictable text generator in a highly regulated industry—knowing that a single hallucination could result in legal liability or public relations disaster—destroys engineering morale. The team spends all its time putting out localized fires instead of building durable, scalable architecture.
As a product leader who has directly managed the deployment of AI-enabled platforms supporting applications processing over $1.6B in monthly transactions at Bank of America, I can definitively state that enterprise survival requires a philosophy of defense-in-depth. In a prototype, you can simply dump an entire 100-page PDF into the context window of GPT-4o to achieve decent reasoning. In production, this approach is disastrous. You are entrusting the untamed output of a foundational model with your user's pristine experience. Instead, mature teams treat AI as a volatile asset that must be fenced in. We enforce strict JSON output schemas, ensuring the model's responses conform exactly to predetermined programmatic shapes. We place secondary, ultra-fast guardrail models synchronously between the primary LLM and the user, automatically intercepting and redacting PII or brand-violating content before pixels ever render on a customer's screens.
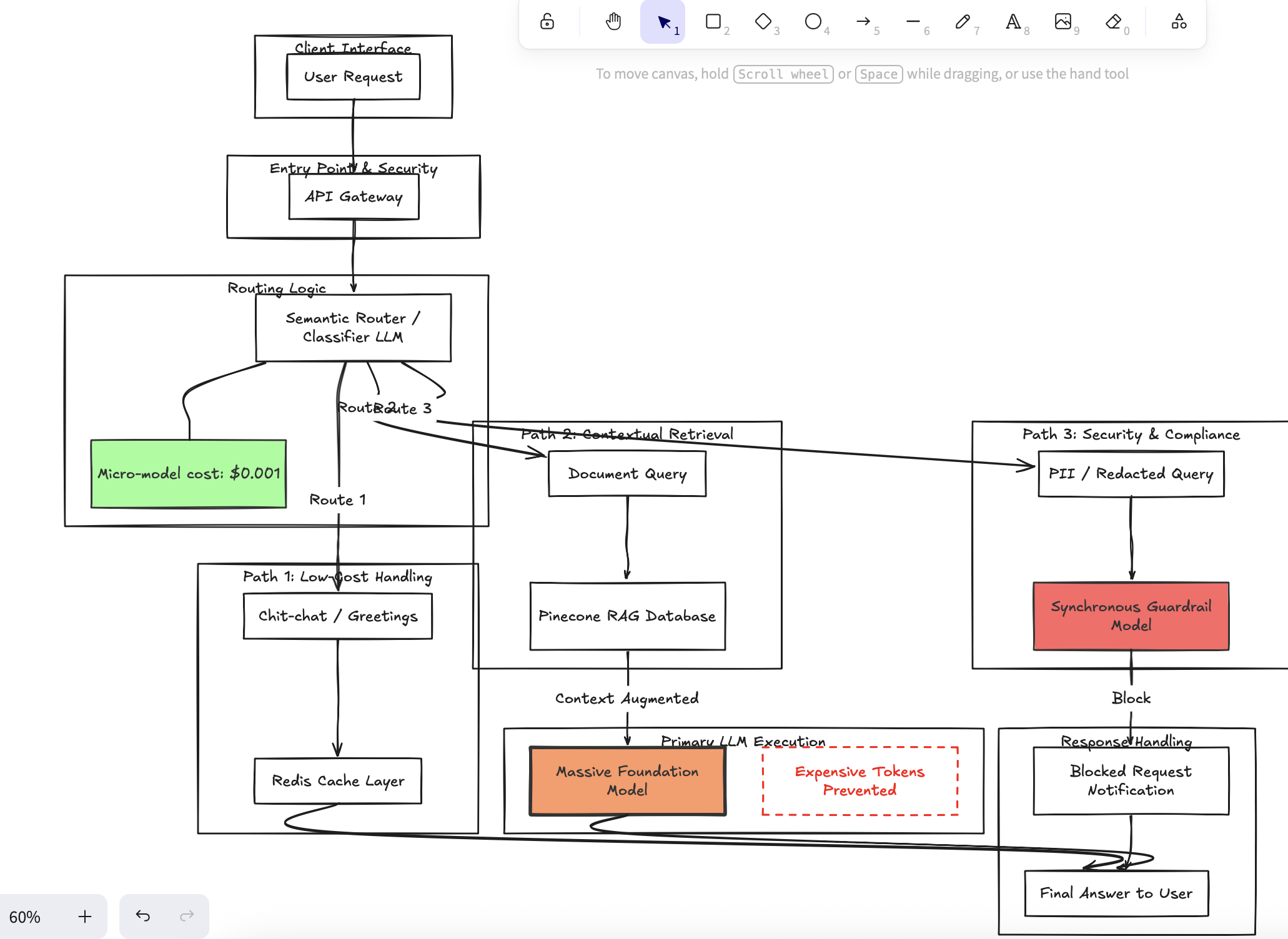
The logic behind this architectural overhaul is grounded in stark, unavoidable corporate economics. Processing a 100,000-token context window for every minor user query will effortlessly bankrupt a software project overnight in pure compute costs via APIs. By replacing lazy context stuffing with optimized Retrieval-Augmented Generation (RAG) tied to semantic routing—where a micro-model costing fractions of a cent decides exactly which subset of data is relevant—companies reduce token expenditure by orders of magnitude (Zaharia et al.). Furthermore, robust observability platforms provide the analytics necessary to correlate non-deterministic text conversations with deterministic business metrics, allowing product teams to actually prove the ROI of the AI feature rather than just guessing.
The gap between a brilliant AI prototype and a shipped AI product is the exact distance between a fleeting parlor trick and a sustainable business. We cannot afford to let the sheer magic of interacting with foundational models blind us to the grueling, meticulous engineering required to wield them safely. The most highly valued technology leaders over the next decade will not be the researchers chasing the next parameter-count breakthrough, but rather the operators who know how to anchor chaotic, probabilistic intelligence into strict, profitable enterprise systems.
Works Cited Zaharia, Matei, et al. "The Shift from Models to Compound AI Systems." Berkeley Artificial Intelligence Research (BAIR), 18 Feb. 2024, bair.berkeley.edu/blog/2024/02/18/compound-ai-systems/.